CMU 11611 的课程笔记。介绍 POS 的一些概念和基本算法。
句法(syntax)是 NLP 的骨架,研究单词之间的形式关系
- 单词怎样聚类称为词类(part-of-speech)
- 怎样与相邻的单词组合成短语
- 一个句子的单词与单词之间彼此依赖的方式
这一篇介绍 POS,单词怎样聚类称为词类。
定义
词类 又称为 POS(Part Of Speech)、词的分类、形态类或词汇标记,根据形态和句法功能来定义,有以下特点:
- 分布特征(Distributional)
单词能够出现在相似的环境中
单词有相似的功能 - 形态特征(Morphological)
单词有相同的前缀后缀(词缀具有相似的功能)
在句法结构中有相似的上下文环境 - 无关于含义(meaning),也无关于语法(可以是主语/宾语,等等)
分类
分为两大类:封闭类(closed class) 和 开放类(open class)。
- 封闭类
包含的单词成员相对固定的词类
介词(prepositions)/限定词(determiners)/代词(pronouns)/连接词(conjunctions)/助动词(auxiliary verbs)/小品词(particles)/数词(numerals) - 开放类
不断有新的词被创造出来- 名词
- 专有名词(proper noun)
- 普通名词(common noun)
可数名词(count noun),物质名词(mass noun)
- 动词
- 形容词
- 副词
- 名词

应用
做自然语言处理的相关任务时,往往我们有太多的单词,需要很多的数据来训练规则,而训练的这些规则会非常的 specific。POS 有助于模型的泛化,并帮助 reduce model size,另外,POS 还有以下的应用:
- 提供关于单词及其邻近成分的大量有用信息
如区分名词、动词等
知道一个词是主有代词还是人称代词,就能知道什么词会出现在它的近邻(主有代词+名词,人称代词+动词) - 提供单词发音的信息
有些词既可以做名词也可以做形容词,发音是不同的 -> 更自然的发音 -> 语音合成系统 - 分割词干(stemming)
单词词类 -> 形态词缀 - 用于信息检索/信息抽取
- 自动词义排歧算法/局部剖析(parital parsing)
词类标注及算法
POS tagging,给语料库中的每个单词指派一个词类或者词汇类别标记的过程。
- 输入
单词的符号串和标记集 - 输出
让每个单词都标上一个单独的而且是最佳的标记
主要有三种标注算法:
- 基于规则的标注(rule-based tagging)
一个手工制定的歧义消解规则的数据库,规则说明歧义消解的条件
E.g. 当一个歧义单词的前面是限定词时,就可以判断它是名词,而不是动词 - 随机标注(stochastic tagging)
使用一个训练语料库来计算在给定的上下文中某一给定单词具有某一给定标记的概率
E.g. HMM - 基于转换的标注(transformation-based tagging)
规则+机器学习,规则可以由前面已标注好的训练语料库自动推导出来
HMM
HMM 又称为隐马尔可夫模型,用概率方法进行 POS 标注。假定标注问题可以通过观察周围的单词和标记来解决。对于一个给定的句子或单词序列,HMM 标注算法选择使得下面的公式为最大值的标记序列:
$$P(word|tag)*P(tag|previous \ n \ tags)$$
HMM 通常是针对一个句子来选择最好的标记序列,而不是基于一个单词,二元语法 HMM 标注算法对于单词 $w_i$ 选择标记 $t_i$,使得对于给定的前面的标记 $t_{i-1}$ 和当前单词 $w_i$,其概率最大:
$$t_i=argmax_jP(t_j|t_{i-1},w_i)$$

- Prior p(Y)
language model, likelihood of a tag sequence - Posterior p(x|y)
likelihood of word given ta - find the max for both
Bayes Rule: P(Y|X)=P(Y)P(X|Y)/P(X)
这个模型也可以进行平滑(用NLP 笔记 - Language models and smoothing提到的回退或者线性差值,来避免零概率
用 Viterbi 算法找出概率最大的标记序列,见Hidden-Markov-Models
举个例子: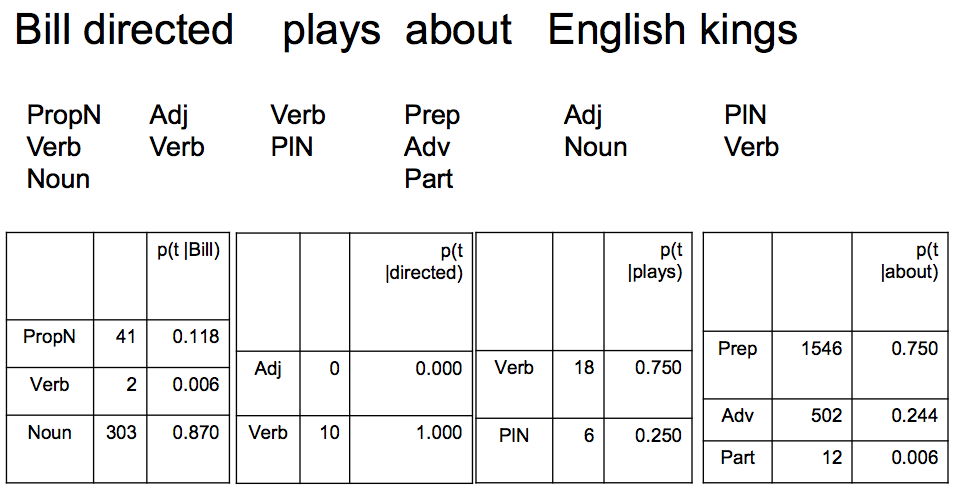
…
Prior: Likelihood of tag sequence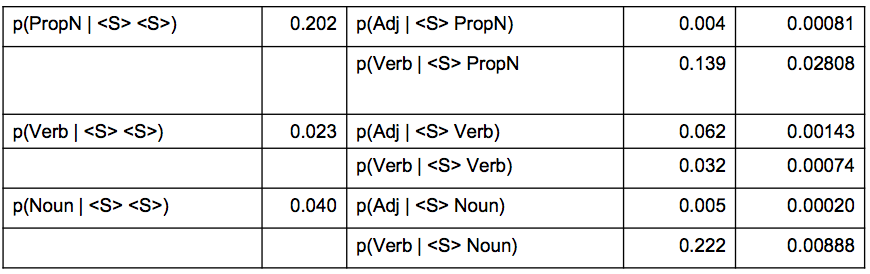
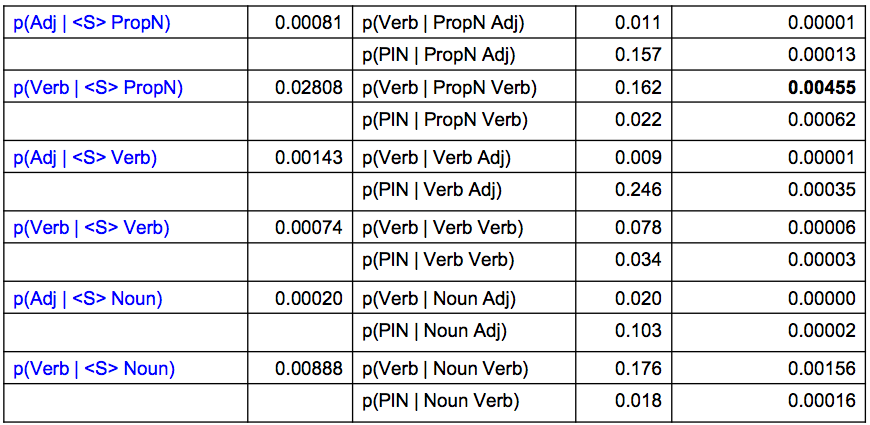
…
Posterior: MLE of word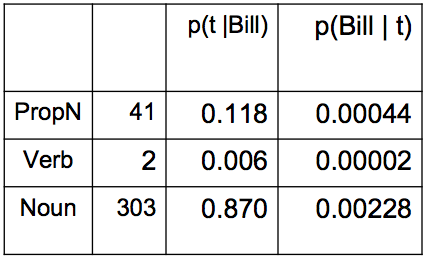
…
注: P(PropN|Bill) = P(Bill|PropN) * P(PropN|Start) / P(Bill),这里没有给出 P(Bill)。
Unsupervised PoS Tagging
如果单词有相同的上下文(前驱词和后继词分布),那么它们也会有相同的标记,所以
- 找到所有的上下文:w1 X w2
- 找到频率最高的 Xs,然后给 Xs 标记
- 重复以上过程,直到终止条件(自定义)
对英语来说,可以重复 20 次
E.g. BE/HAVE MR/MRS AND/BUT/AT/AS TO/FOR/OF/IN VERY/SO SHE/HE/IT/I/YOU
然而没有 Nonuns/Verb/Adj 这些识别标记
Brown Clustering
是一种自底向上的层次聚类算法(hierarchical agglomeretive),基于 n-gram 模型和马尔科夫链模型。是一种硬聚类(hard clustering),每一个词都在且只在唯一的一个类中。
- 输入:语料库
- 输出:二叉树
树的叶子节点是一个个词,每个词用类似霍夫曼编码的方式进行编码
树的中间节点是我们想要的类(中间结点作为根节点的子树上的所有叶子为类中的词)
容易 scale
基本思想: 初始的时候,将每一个词独立的分成一类,然后,将两个类合并,使得合并之后 quality 函数最大,然后不断重复上述过程,达到想要的类的数量的时候停止合并。quality 函数,是对于 n 个连续的词(w)序列能否组成一句话的概率的对数的归一化结果。跟踪 cluster 合并的过程,可以从下往上建一个二叉树,每一个单词都被表示为一个 binary string(从根到叶子节点的路径),每一个中间的节点都是一个类。
Quality = merges two words that have similar probabilities of preceding and following words
(More technically quality = smallest decrease in the likelihood of the corpus according to a class-based language model)
关于 class-based language model,可以看Class-Based n-gram Models of Natural Language
形成的二叉树: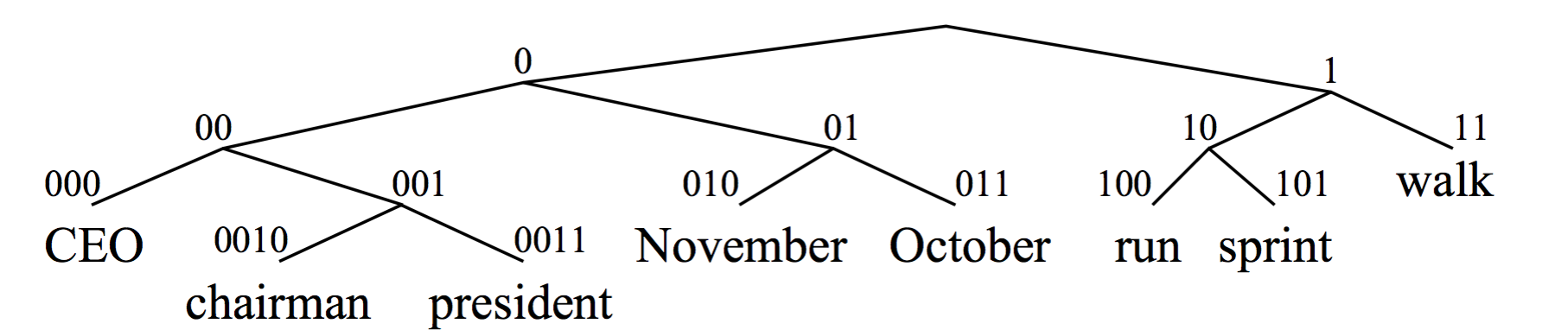
算法:
补充算法 Feature-based tagger
——————————————–我是分界线——————————————–
之所以叫补充算法,是因为上面所述的算法来自书/PPT,而下面的算法来自 stanford 讲义
Sequence Labeling as Classification
|
|
然后训练一个分类器来预测 tag,当然特征也可以引入上下文(sliding window),这种方法称为 Sequence Labeling as Classification



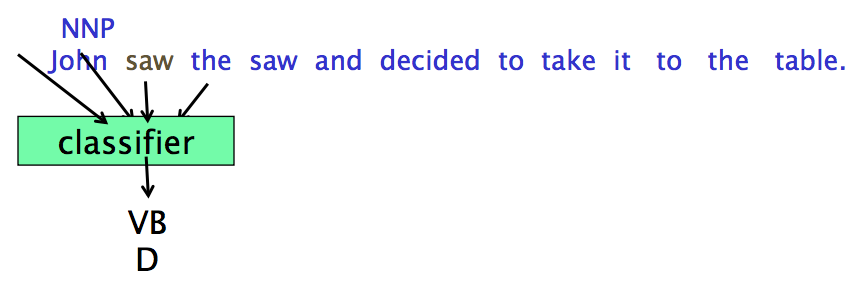
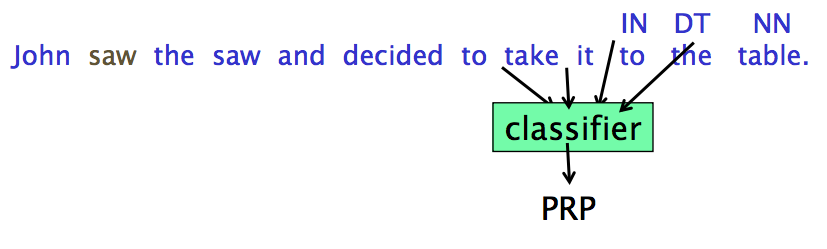
更好的特征往往是当前 token 前后 token 的类别,但是我们不知道这些类别,所以要往前/往后看,使用之前的 output
Forward Classification

Backward Classification

Maximum Entropy Markov Model(MEMM)
A sequence version of the logistic regression(also called maximum entropy) classifier
找到最佳的标记序列,基础算法:
$$
\begin{aligned}
\hat T & = argmax_T P(T|W) \\
& = argmax_T \prod_i P(t_i|w_i,t_{i-1}) \\
\end{aligned}
$$
每个 tag 的特征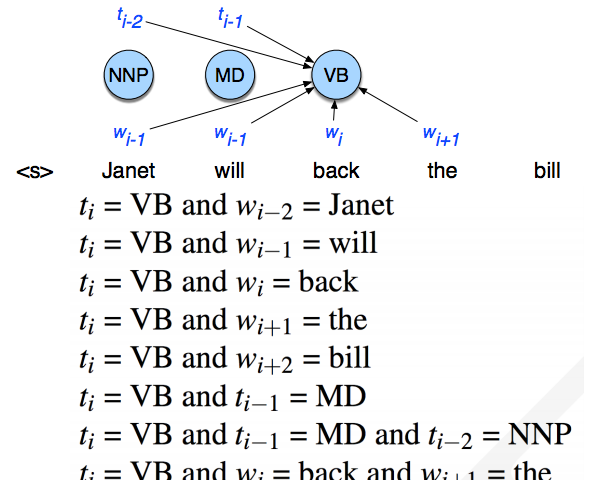
更多 feature
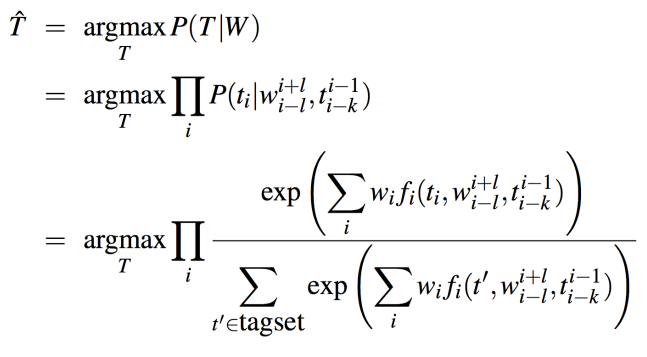
用 Viterbi 算法来实现
未知词
如何来估计未知词的标记?大概有下面几种办法
- 假定每个未知词在所有可能的标记中都是有歧义的,也就是说都具有相同的概率
根据上下文相关的 POS trigram 给未知词恰当的标签 - 在未知词上的标记的概率分布与在训练集中只出现一次的单词的标记的概率分布非常相似
与NLP 笔记 - Language models and smoothing提到的 Good-Turing smoothing 思想类似 - 使用关于单词拼写的信息
4 类特殊的正词法特征,包括 3 个屈折词尾(-ed,-s,-ing),32个派生后缀(-ion,-al,-ive,-ly),4个大写(captial)值(首字母大写,非首字母大写等)以及连字符(hyph)规则
$P(w_i)=P(unknown-word|t_i)P(captial|t_i)P(endings|hyph/t_i)$
小结
各种方法的准确率
词类标注是歧义消解(disambiguation) 的一个重要方面。英语中大多数单词是没有歧义的,然而最常用的单词很多都是有歧义的,如 can 可以是助动词,也可以是名词,还可以是动词,POS 标注的问题就是消解这样的歧义,在一定的上下文中选择恰如其分的标记。
E.g.
参考链接
Brown Clustering算法和代码学习
Brown Clustering && Global Linear Models

